文档和资源
要注意的点
Packages
每个go程序都由package构成。
Exported name
在一个包中,如果一个name是以大写字母开头的,那么这个name将会被从这个包中导出。
当import一个包的时候,只能引用被导出 的name。
函数
参数
参数名称在前,类型在后,Go's Declaration
Syntax 。
当多个连续的函数参数有共同的类型是,可以省略不写除最后一个外的类型。
1 2 3 func add (s string , x, y int ) int { return x + y }
返回值
一个函数可以返回任意个数的结果。
返回值可以是有名字的。当return不带任何参数时,函数返回named
return values,这叫做"naked" return。
1 2 3 4 5 func split (sum int ) int ) { x = sum * 4 / 9 y = sum - x return }
变量
var声明多个变量时,只能写最后一个的类型。
如果声明时给出了初始值,那么会以初始值的类型作为变量的类型,此时声明中的类型可省略。
在函数内部可以用短变量声明:=来声明变量,类型由值的类型来决定。但在函数外部,由于所有语句都需要以关键字开头,因此不可用这个方法。
初始化
在声明变量的时候,变量的值总是会被初始化,要么是用指定的值,要么是零值(变量类型的默认值)。
基本数据类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 bool string int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr byte rune float32 float64 complex64 complex128
声明变量但不显式给出初始值,变量会被赋予零值。数值类型:0,bool类型:false,string:""。
类型转换和推断
在进行类型转换时,go只能使用显式 类型转换。
使用:=或var =声明变量、未指明类型、但给出初始值时,变量的类型由对初始值进行类型推断得到。如果右侧是数值常量,那么变量的类型可能是int,float64,complex128。
常量
只可以用const来声明。数值常量可表示任意精度,且不会溢出。一个未指定类型的常量由上下文来决定其类型。
全局变量
在程序运行期间,始终存在。声明和初始化方式与普通变量相同,需要在函数外部声明。
语句
for
1 2 3 4 5 6 7 8 9 10 11 12 for i := 0 ; i < 10 ; i++ { ... }for ; sum < 1000 ; { ... }for sum < 1000 { ... }for { ... }
if
1 2 3 4 5 6 7 8 9 10 11 12 if x < 0 { ... }if v := math.Pow(x, n); v < lim { ... }if v := math.Pow(x, n); v < lim { ... } else { ... }
switch
求值顺序,按case的顺序,自上向下进行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 switch os := runtime.GOOS; os { case "darwin" : fmt.Println("OS X." ) case ... ... switch { case t.Hour() < 12 : fmt.Println("Good morning!" ) case ... ...
defer
使用defer时,被defer的函数会被push到一个stack,参数会立即计算 ,但函数结束时,stack中的函数才会被pop出来执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func t (s string ) string { fmt.Printf("in func t: %s\n" , s) return s } func main () { defer fmt.Println(t("you" )) fmt.Println("hello" ) } }
defer的函数可以读取和赋值到函数的返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 func c () int ) { defer func () return 1 } func c1 () int ) { var i int defer func () return 1 }
defer、panic和recover
当调用panic时,所有defer的函数都被正常执行。然后函数返回到调用者。
recover仅在defer的函数中有用,正常执行时调用,只会返回nil。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 func main () f() fmt.Println("Returned normally from f." ) } func f () defer func () if r := recover (); r != nil { fmt.Println("Recovered in f" , r) } }() fmt.Println("Calling g." ) g(0 ) fmt.Println("Returned normally from g." ) } func g (i int ) if i > 3 { fmt.Println("Panicking!" ) panic (fmt.Sprintf("%v" , i)) } defer fmt.Println("Defer in g" , i) fmt.Println("Printing in g" , i) g(i + 1 ) }
其他类型
关于slice,map和channel,某些书中会将它们描述为引用,但从实现上看(例如:slice 、map 、chan ),这些类型不过只是封装了底层指针的struct,且go
spec也早就在文档中移除 了reference一词的使用,而在THE
WAY TO GO一书中虽然使用了reference一词,但也明确指出,
A reference type variable r1 contains the address (a number) of the
memory location where the value of r1 is stored. ... When assigning r2 =
r1, only the reference (the address) is copied. ... In Go pointers (see
§ 4.9) are reference types, as well as slices (ch 7), maps (ch 8) and
channels (ch 13). ......
指针
存储了内存地址,零值为nil。&获得变量的地址,*解引用。
对比c的指针,go的指针无法进行算数运算。
1 2 3 4 var p *int i := 42 p = &i
指针的类型转换
unsafe.Pointer:type Pointer int,代表了变量的内存地址,可以将任意变量的内存地址与Pointer指针相互转换。
uintptr:type uintptr int,Pointer无法进行加减运算,需要转换为uintptr才可以,可以将Pointer与uintptr指针相互转换。
unsafe.Offsetof:可以得到字段在结构体内的偏移量。
1 2 3 4 5 6 7 8 9 10 11 12 13 *T <=> unsafe.Pointer <=> uintptr type Vertex struct { X int Y int } var v = Vertex {50 , 50 }var x = *(*int )(unsafe.Pointer(&v))var y = *(*int )(unsafe.Pointer(uintptr (unsafe.Pointer(&v)) + uintptr (8 )))var y = *(*int )(unsafe.Pointer(uintptr (unsafe.Pointer(&v)) + unsafe.Offsetof(v.Y))
Struct
字段的集合,使用.来访问字段。首字母大写和小写分别代表公开和私有。私有变量只有同一个package才可以访问。
对于struct指针,可以使用(*p).X或直接使用p.X来进行访问。对比c,go不能用->来访问成员。
初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 type Vertex struct { X int Y int } var v1 = Vertex { X: 1 , Y: 2 , } var v2 = Vertex { X: 1 , } var v3 = Vertex { X: 1 }var v4 = Vertex {}var v5 = Vertex { 1 , 2 }var v6 *Vertex = &Vertex { 1 ,2 }var v7 *Vertex = new (Vertex)var v8 Vertexvar v9 *Vertex = nil
copy *
结构体之间的copy是深拷贝,不共享结构体内部字段。 *
结构体指针的copy是浅拷贝,共享内部字段。
组合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 type Vertex struct { X int Y int } type Circle1 struct { v Vertex Radius int } type Circle2 struct { Vertex Radius int }
Array
和c一样,数组的大小也是数组类型的一部分,声明数组时必须有大小,通过下标访问数组中的元素。
程序执行时,go会检查访问是否越界。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 var a[10 ] int var a = [6 ] int {2 , 3 , 5 , 7 , 11 , 13 }var b[6 ] int = [6 ] int {2 , 3 , 5 , 7 , 11 , 13 }c := [6 ] int {2 , 3 , 5 , 7 , 11 , 13 } d := [...] int {2 , 3 , 5 } e := [5 ] int {1 : 10 , 2 : 20 } primes := [6 ]int {2 , 3 , 5 , 7 , 11 , 13 } var e[6 ] int e = a
内部存储 连续分配的内存区域。
copy
数组的类型由元素的类型和数组的大小决定,相同类型的数组之间才可以copy。拷贝一个数组,数组的内部的元素也会被逐一拷贝,因此作为变量传递时,需要注意copy的开销。
Slice
slice的类型为[]int,对数组进行, *
a[low_index:high_index]后得到,区间是前闭后开,可以省略low_index或high_index,默认值分别为0和数组长度。
cap(a) = len(array) - low_index *
a[low_index:high_index:cap_index]后得到,区间是“闭、开、开”。cap_index代表可用到的底层数组的最大index,必须小于len(array)。
cap(a) = cap_index - low_index
1 2 3 4 var a[10 ]a[:4 ] a[:] b := []string {99 : "" }
内部存储 1 2 3 4 5 6 7 8 +---------------+ slice: |pointer|len|cap| +--+------------+ | | +--v--------------+ array: |item1|item2|... | +-----------------+
例如: 1 2 3 4 5 6 s := []int {2 , 3 , 5 , 7 , 11 , 13 } var s = []int {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 }var address = (**[10 ]int )(unsafe.Pointer(&s)) var len = (*int )(unsafe.Pointer(uintptr (unsafe.Pointer(&s)) + uintptr (8 )))var cap = (*int )(unsafe.Pointer(uintptr (unsafe.Pointer(&s)) + uintptr (16 )))
slice和array
slice本身并不存储任何数据,仅仅是数组选定区间的描述,和数组共享底层的数据。len()和cap()对应了slice的长度,和底层数组从low起的大小,即:len(array) - low。
对已有slice再做一次slice,实际上是改变slice对底层数组的引用范围。
1 2 3 4 5 6 7 s := []int {2 , 3 , 5 , 7 , 11 , 13 } s = s[:0 ] s = s[:4 ]
slice字面值类似数组的,区别是没有大小。底层实际上创建了相同大小的数组,然后再创建slice。
nil slice 一个nil
slice,是未初始化的slice,len和cap都为0,且不会分配底层的数组,数组指针为nil。
空slice
一个空slice的len和cap都为0,且不会分配底层的数组,数组指针值不为空,但是也未分配底层数组。
1 2 a := make ([]int , 0 ) b := []int {}
当想声明一个空的slice时,nil
slice和空slice都可以,两者在功能上完全等价,但是更推荐 nil
slice。但二者进行序列化的时候,结果会不同,nil
slice会编码为null,而空slice是[]。
make slice
通过make来创建动态长度的数组。
1 2 3 4 a := make ([]int , 5 ) b := make ([]int , 0 , 5 ) var c []int = make ([]int , 5 )var d = make ([]int , 5 )
append
append函数能够将相同类型元素追加至现有slice,若底层数组大小不够,则会重新分配内存,并将slice指向新数组。
如果发生了扩容,且有另一个slice存在,那么另一个slice的仍然指向老的数组。
扩容时,如果cap < 1024,那么会扩100%,否则扩25%。
1 func append (s []T, vs ...T)
range
除了普通方法遍历slice,还能使用range,
1 2 3 4 5 6 7 8 9 for i, v := range s { ... }for _, value := range s { ... }for i, _ := range s { ... }for i := range s { ... }
当使用range返回的值,v时,要注意的是 range返回的是元素的copy ,而不是引用,如果对齐进行&,那么得不到期望的结果。具体来说,Go会使用同一个 变量,在每轮迭代中保存元素的copy。可以使用kyoh86/scopelint 来检查代码中的unpinned
variables。
取地址。
1 2 3 4 5 a := make ([]int , 5 ) for i, v := range a { fmt.Println(&v, &a[i]) }
这个原因还有可能导致使用goroutine时出现意外 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 for _, val := range values { go func () fmt.Println(val) }() } for _, val := range values { go func (val interface {}) fmt.Println(val) }(val) } for i := range valslice { val := valslice[i] go func () fmt.Println(val) }() }
copy
slice的copy是浅拷贝,两个slice共享底层数组。本质上copy的是:指向底层数组的指针、len和cap。
1 2 a := []int {2 , 3 , 5 , 7 , 11 , 13 } var b = a
go还提供了一个函数copy来实现数组内容的copy,copy时,会以目的切片的容量为准。
1 func copy (dst, src []T) int
结合slice的内部存储、append和拷贝,有的使用场景不注意可能导致意料之外的结果。
1 2 3 4 5 6 7 8 9 10 11 12 func FuncSlice (s []int , t int ) s[0 ]++ s = append (s, t) s[0 ]++ } func main () a := []int {0 , 1 , 2 , 3 } FuncSlice(a, 4 ) fmt.Println(a) }
具体过程分析如下: 1.
s[0]++:a和s都指向同一个底层数组arr1,此时a->arr1,s->arr1,修改了arr1。
2.
append:由于扩容,append返回了一个新的底层数组arr2,a->arr1,s->arr2。
3.
s[0]++:修改了arr2,arr1不变。
Map
一个仅做了声明的map是nil,需要使用make来进行初始化。切片、函数以及包含切片的结构类型这些类型由于具有引用语义,不能作为映射的key,使用这些类型会造成编译错误。
1 2 3 4 5 6 7 8 9 10 11 type Vertex struct { Lat, Long float64 } var m map [string ]Vertexfmt.Println(m == nil ) m = make (map [string ]Vertex) m["Bell Labs" ] = Vertex{ 40.68433 , -74.39967 , }
map字面值和struct字面值类似。
1 2 3 4 5 6 7 8 var m = map [string ]Vertex{ "Bell Labs" : Vertex{ 40.68433 , -74.39967 ,} } var m = map [string ]Vertex{ "Bell Labs" : { 40.68433 , -74.39967 ,}, }
mil map nil
map未进行初始化,不能用于存储key-value。
make map 通过make来创建map。
1 var m = make (map [string ]Vertex, 10 )
range
类似slice,且slice中存在的问题,map中也同样存在。由于无法获取index,因此只能通过每轮迭代创建变量来解决。
1 2 3 4 5 6 7 8 9 for k, v := range m { ... }for _, v := range s { ... }for k, _ := range s { ... }for i := range s { ... }
操作 * 新增和更新:m[key] = elem *
访问key的值:elem = m[key],如果不存在,那么elem为此类型的零值,但如果值真的是零值,那通过这个方法来判断key是否存在就失效了。
* 删除:delete(m, key) *
test:var elem, ok = m[key],如果不存在,那么elem为此类型的零值。
字符和字符串
rune
rune字面值代表一个rune常量,是一个标识Unicode code
point的整型值。alias for int32。
rune字面值可以用'单个字符'来表示,可以用\转义的多个字符来表示,具体见Rune literals 。
string
string字面值代表了包含一系列字符的string常量,只读。有两种形式:raw
string字面值和interpreted string字面值。
raw string字面值,是经过未转义处理的,在raw
string内部,可以出现任意字符。string中出现的'\r'会被忽略。
interpreted string字面值,go会进行转义处理。具体见String
literals
1 2 3 fmt.Println("\U000065e5\U0000672c\U00008a9e") \\ 日本語 fmt.Println(`\U000065e5\U0000672c\U00008a9e`) \\ \U000065e5\U0000672c\U00008a9e
内部存储 1 2 3 4 5 6 7 8 9 10 11 12 +---------------+ byte slice: |pointer|len|cap| +--+------------+ | | +--v------------+ array: |item1|item2|...| +---^-----------+ | +---+-----------+ string: |pointer|len|cap| +---------------+
1 2 3 4 5 a := "Hello,你好" fmt.Printf("%x\n" , *(*[2 ]int )(unsafe.Pointer(&a))) \\ [4 b9f3c e] b := a fmt.Printf("%x\n" , *(*[2 ]int )(unsafe.Pointer(&b))) \\ [4 b9f3c e]
由于底层存储是数组,因此可以做slice,但要注意的是,这里本质上是对字节来做slice,因此如果slice的Unicode
code point不是一个完整的字符,那么打印的时候,是不会正确显示的。
1 2 3 a := "Hello,你好" b := a[0 :9 ] fmt.Println(b) \\ Hello,�
从字符串得到字节slice或者从字节slice得到字符串,会发生底层数组的copy。如果想避免copy,可以手动一个string或slice,获得一个原始string或者slice的“reference”,这种方式不可以通过slice修改string,因为修改后,“reference”到的原有string失效了,可能会被gc回收。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 a := "Hello,World" b := []byte (a) c := string (b) func str2bytes (s string ) byte { var strhead = *(*[2 ]int )(unsafe.Pointer(&s)) var slicehead [3 ]int slicehead[0 ] = strhead[0 ] slicehead[1 ] = strhead[1 ] slicehead[2 ] = strhead[1 ] return *(*[]byte )(unsafe.Pointer(&slicehead)) } func bytes2str (bs []byte ) string { return *(*string )(unsafe.Pointer(&bs)) }
遍历 * 按字节遍历:通过下标。 *
按字符遍历:range方式遍历。
Function values
函数也是值,可作为参数传递,作为返回值返回。
闭包(closure)是function
value引用了函数体外部的变量,函数可以访问和修改这些变量。换句话说,闭包包含了函数、以及所在的环境的上下文 。
方法和接口
方法集(method sets)和调用
方法集 和函数调用 的规范明确了一个类型有哪些方法 ,以及在什么时候可以调用 什么样的方法。go
wiki上关于这两个概念有比较详细的例子 。
method set 1. 对于一个接口类型,接口是方法集。
对于一个类型T,所有receiver为T的方法是方法集。
对于类型T对应的指针类型*T,所有receiver为T或*T的方法是方法集。
interface type
interface
T
func (T) f()
*T
func (*T) f(), func (T) f()
一个类型T的方法集决定了,这类型T的接口类型的实现,和使用T作为receiver时可以被调用的方法。
call 对于一个方法调用x.m(), 1.
如果x的method
set包含m(),且调用时的参数列表合法,那么这个调用是合法的。
如果x可以取地址的 ,并且&x的method
set包含m(),那么x.m()等价于(&x).m()。
map元素和interface存储的具体值不可取地址。
方法
方法是带有特殊receiver参数(func和函数名之间)的函数。这个receiver不必是struct,但要求receiver的类型定义必须在同一个package里面,且不能直接将内置类型作为receiver。
1 2 3 4 5 type Vertex struct { X, Y float64 }func (v Vertex) float64 { ... }type MyFloat float64 func (f MyFloat) float64 { ... }
Point receiver 若要修改字段,则必须使用point
receiver,无论变量本身是否是指针类型 ,非指针receiver调用时发生了copy 。
从这里可以得出使用point receiver的场景:1. 避免copy;2.
修改值本身。一般来说,某个类型的receiver应该统一 ,要么是point
receive,要么是普通receiver。
1 2 func (v *Vertex) float64 ) { v.X = v.X * f ... }func (v Vertex) float64 ) { v.X = v.X * f ... }
若v不是指针类型,那么go会把v.Scale自动转换为(&v).Scale。
反过来,若v是指针类型,在调用Scale2时,go会把v.Scale2转换为(*v).Scale2。
对比c++的成员函数,this指针类似于point
receiver,但go的普通receiver是不同于c++的。
接口
接口是方法签名的集合。
接口的实现是隐式的,无需类似implement的关键字。隐式实现解耦 接口的定义和实现,在package中,接口的定义可以出现在方法和类型定义之后。注意方法的实现区分普通receiver和point
receiver 。
一个接口值可以被赋值为任何实现了接口中所有方法的值 。接口值底层实际包含了具体值的类型,接口值可以看做是值和具体类型的元组。调用接口值的方法,实际上会调用具体类型的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type Abser interface { Abs() float64 }type MyFloat float64 func (f MyFloat) float64 { ... }type MyInt int64 func (f MyInt) int64 { ... }type Vertex struct { X, Y float64 }func (v *Vertex) float64 { ... }var a Abserf := MyFloat(1 ) i := MyInt(2 ) v := Vertex{3 , 4 } a = f a = i a = &v
对比c++的多态,c++中通过继承基类,并覆盖基类的虚函数,在运行时进行动态绑定,以此实现多态。go的接口方法定义可以看做是基类和虚函数,而a = f相当于将子类的指针赋值给基类指针,这样完成了动态绑定。
不同的点还是receiver,实现接口的方法时,go区分了point
receiver和普通receiver。
内部存储
实现上,一个接口值底层包含了指向类型和数据的指针。
接口类型之间的赋值和类型转换是共享数据的,而结构体之间的赋值、结构体转接口、接口转结构体,都会导致数据的copy。
空的具体类型值
如果接口的具体类型值是空的,那么将会使用nil
receiver来调用方法,不引发空指针异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type Abser interface { Abs() float64 }type Vertex struct { X, Y float64 }func (v *Vertex) float64 { if v == nil { ... } ... } var i Abservar v *Vertexi = v i.Abs() v.Abs()
空的接口值
会发生运行时错误,没有具体的Abs方法可以调用。
1 2 3 type Abser interface { Abs() float64 }var i Abseri.Abs()
空接口 空接口的值可以包含任何类型。
1 2 3 4 5 6 var i interface {} i = 32 i = "hello" // i = 100000000000000000000000000 // overflows int
接口变量的赋值
对于数值类型,底层的具体类型只能是 int,float64,complex128。
类型断言
类型断言提供了访问接口底层具体类型值的能力。
t := i.(T)断言接口i拥有具体类型T,并把类型T的值赋值给t。如果不是类型T,则触发panic。test:t, ok := i.(T)断言不正确的情况,不触发panic,而是ok为false,且t为类型T的零值。
1 2 3 4 5 var i interface {} = 100000000000000000000000000 a := i.(int64 ) var i interface {} = 100000 a := i.(int64 )
Type
swtiches是允许断言多个类型的结构。类似switch语句,但是每个case是特定的类型。
1 2 3 4 5 6 7 8 9 10 switch v := i.(type ) {case T: case S: default : }
对比scala的pattern matching,go的type swtiches像,但不是pattern
matching。scala的pattern
matching会检查值和pattern是否匹配,能够把值解构为构成值的各部分。猜测 go的type
swtiches是类型字符串是否相等的test。
一些内置的接口
Stringer
类似python的__str__,定义在fmt中。
1 2 3 4 5 6 7 8 9 type Stringer interface { String() string } type A ...func (a A) string { return "hello" }a := A() fmt.Println(a)
error
类似Stringer,fmt在print的时候也会查找error接口。从fmt的实现上看,是error优先 。
1 2 3 type error interface { Error() string }
error更适合用于专门定义的错误类型。否则功能上,stringer和error就冗余了。
可以使用fmt.Errorf或errors.New来创建error类型的值。
1 fmt.Errorf("math: square root of negative number %g" , f)
Reader
io包定义了io.Reader接口,代表读取stream,有多个实现(文件、网络等)。
其中func (T) Read(b []byte) (n int, err error)方法使用现有数据填充b,并返回填充的字节数和error。stream结束时,error为io.EOF。
并发
Goroutines
由go运行时管理的轻量级线程。
参数的计算在当前goroutine中完成,函数f的调用发生在新的goroutine。所有子协程都是平级的关系(包括在子协程内部启动另一个协程)。
Channels
channel是带类型的管道(typed
conduit),每次只能发送或接受一个元素。默认情况下,发送方和接收方会一直阻塞到另一方ready,每次只能唤醒一个发送或接受方。
方向 1 2 3 chan T chan <- T <-chan T
unbuffered channel unbuffered
channel必须保证先有goroutine正在接收,否则发送方会一直阻塞到有goroutine来接收为止。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ch := make (chan int ) ch <- 1 v := <-ch go func () v := <-ch fmt.Println(v) }() ch <- 1
buffered channel
ch := make(chan int, 100),buffered
channel在满或空的情况下,分别会导致发送方和接收方阻塞。
range
for i := range ch可以从channel逐个接收值,直到channel被关闭。
close *
发送方可以通过close(ch)来告诉接收方没有后续的值会发送。如果向关闭的channel发送元素,那么会导致抛出异常。
*
接收方可以使用v, ok := <-ch判断channel是否被关闭。如果从一个已经关闭的channel接收元素,会返回channel类型的零值,因此是不能用这个方式来判断channel是否关闭的。
select
select语句可以让goroutine等待多个通信操作(发送或接受都可以),block直到其中某个case能执行。如果同时有多个case能执行,则随机选择一个。
若存在default,则当没有case
ready的时候,执行default,因此可以通过default实现非阻塞式的发送或接受。
1 2 3 4 5 6 select {case i := <-c: default : }
并发模式
内存模型
go内存模型
反射
构建
static build
go build启用race,也需要启用cgo。
测试
总结
抛开go的运行时环境和gc不说,go很像c,同时还有着少量函数式语言的特性。
go中,我很喜欢的几点是:
变量和函数的声明简洁清晰
goroutine
提供了CSP来实现goroutine之间的通信
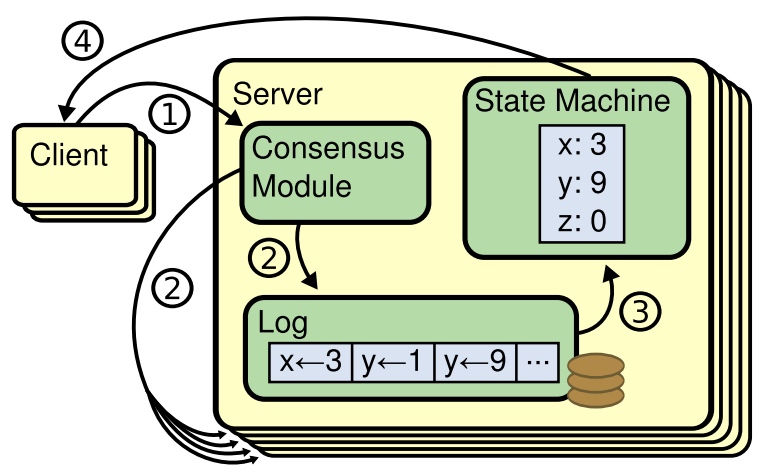
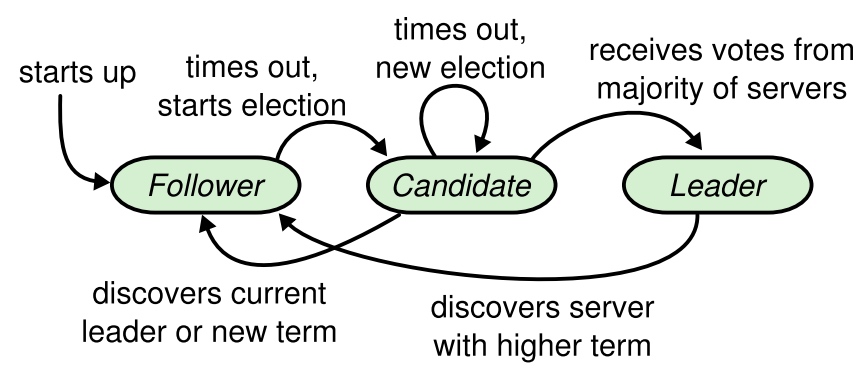
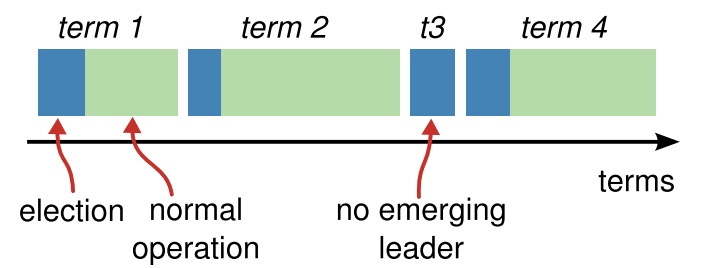
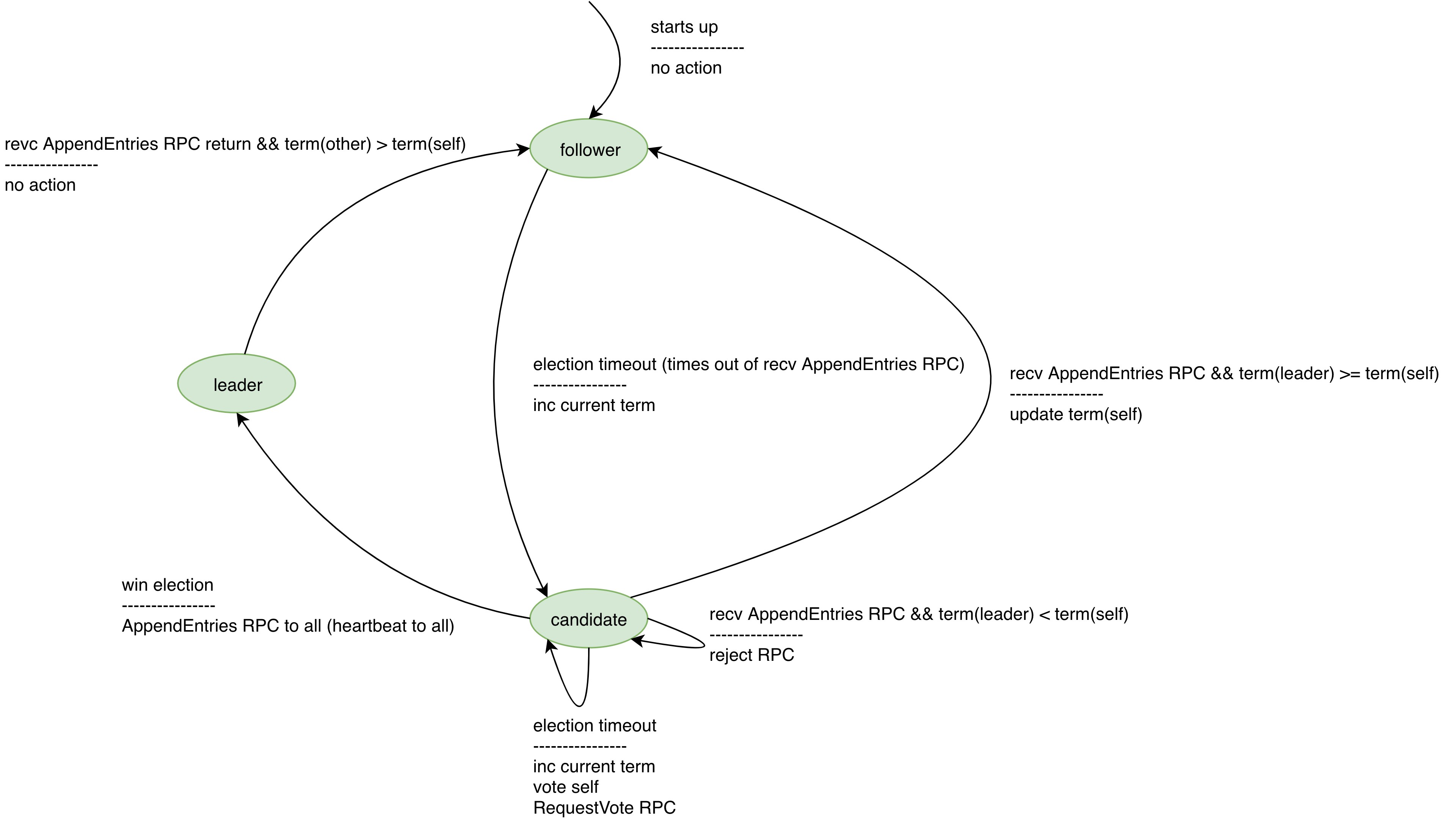
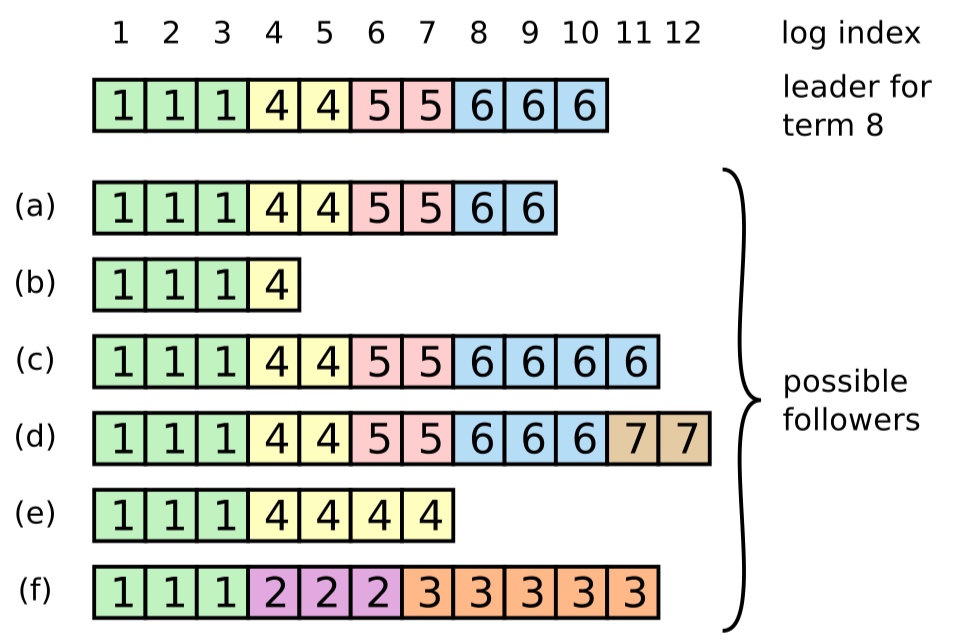
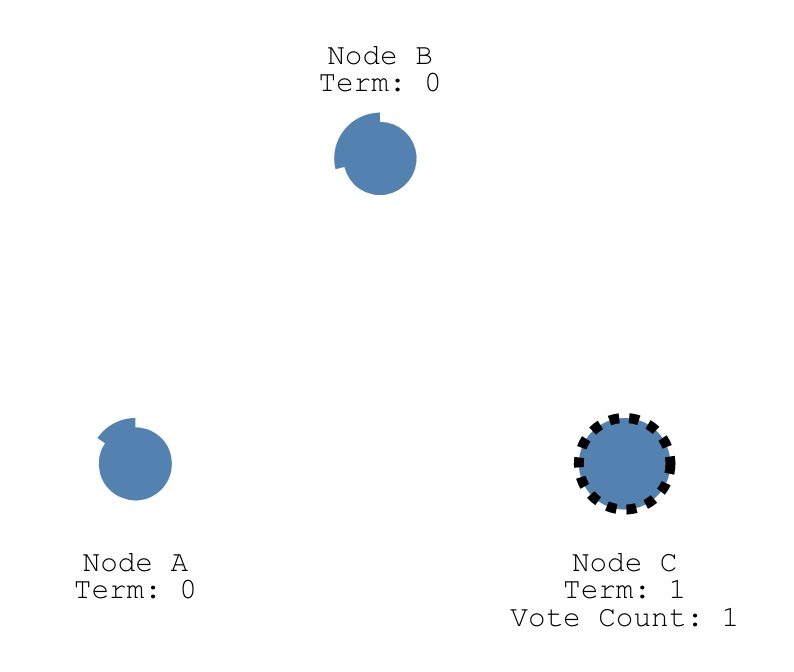 * 且split votes能够被快速解决。如果出现split
votes,candidate先等待随机election timeout。
* 且split votes能够被快速解决。如果出现split
votes,candidate先等待随机election timeout。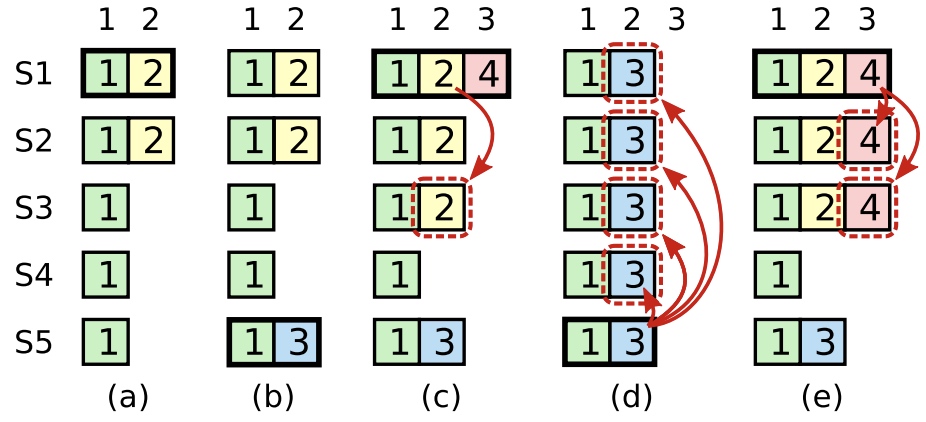


 云南昆明,2019-02-08
23:57
云南昆明,2019-02-08
23:57 内蒙包头,2019-05-02
23:49
内蒙包头,2019-05-02
23:49