入手比亚乔x7
- 入手了比亚乔 x7 ,主要通勤用,简单记录相关的事项,供有需要的读者参考。后续可能会随着使用不断更新。
需求
基本需求
- 通勤,摩托车路线,单程 30km,来回 60km。位于北京,京 B 不能进入四环(包括四环主路)。
- 周末买菜,去周边走走。和家人一起出去就考虑公交和开车了。
- 家人建议买踏板。
- 因此,车型定为踏板。另外通勤距离较长,不想经常加油,需要油箱大一点的,最终选择了比亚乔 x7。
通勤成本
- 比亚乔 x7,油箱 12.1L,城市通行平均油耗约 3.5L/100km,95 号汽油约 7.5 元/L,假设工作日平均每天 65km,节假日平均每天 50km,
- 成本: \((65*20+50*8)/100*3.5*7.5=446.25\) 元。
- 续航: \(12.1/3.5=345km\) , \(345-65*5=20km\) ,基本足够工作日通勤。
- P.S. 可以使用 小熊油耗 记录。
驾照
- 增驾的时候可选 E(两轮)或 D(三轮),我选择的是 D,增驾完成后两轮和三轮都能骑,驾校学习+考试总共约 1900 元。
- 在北京学摩托相对严格些,科目一和四需要刷视频课时,然而一般就是点开放着,基本没有人会正儿八经看完;科目二和三练车也需要刷够课时,主要的时间就花在这个上面了。最终考试的时候,车上配有雷达和传感器,检测必要的身体动作和车的位置。这样学习和考核难度其实已经很低了,不过我还看到有的地方能一天拿本,实在是无力吐嘈。
- 参考日本的摩托驾照,我觉得国内 E 和 D 的划分明显是不合理的。就两轮摩托而言,骑行大排量和小踏板需要的技能是有不少区别的,我刚拿到 D 照的第三天就看到新手骑大排上高速 gg 的新闻。
装备和改装
装备
头盔
- 全盔,相对来说安全性最高。
- 安全认证(参考摩托车头盔安全认证DOT、ECE、Snell)认准 SNELL、SHARP 即可,3C、ECE、DOT 认证比较基础。
骑行服,手套,护具
- 按季节不同,分不同款式,购买带护具的会方便些。
- 春夏秋
- 骑行服+护膝+手套。没有骑行裤,需要一个雨衣裤子来应对下雨天气。
- 冬
- 冬季骑行服+护膝+手套+滑雪脖套。
- 春夏秋
- 按季节不同,分不同款式,购买带护具的会方便些。
改装
- 改装主要是围绕安全性和功能性。下面列出了计划要做的改装,实际不一定都改,看实际使用情况。
- 査车主要针对的是外观和噪音,但是要注意,查得严的时候,尾箱、保险杠、手机支架、小黄鸭装饰等都算作非法改装。
item detial product experience 头盔 需要考虑头围和头型 LS2396,摩雷士R50S,比亚乔赠送半盔 LS2396无法放入坐桶,比亚乔赠送半盔可放入座桶 骑行服 带护具 NERVE春夏款,sbk冬款 在最冷的那几天,sbk冬款需要内搭一件薄羽绒服才不冷 骑行裤 赛羽速脱裤 冬季必备 手套 防水,带护具 NERVE春夏款,外星蜗牛冬款 手把套 防水 淘宝手把套 冬季必备,手套的防风效果还是有限 护具 骑行服有护具,但是后座带人时需要 雨衣 淘宝雨衣 突然降温,衣物不够时,可以应急使用,防风效果也是很不错的 车锁 U型锁,链锁,碟刹锁,品牌:abus,xena,topdog,kovix XENAXSU-170U型锁,kovixKVX14mm碟剎锁 车衣 淘宝车衣 车把套 advtech车把套 后视镜 GW250后视镜+凸面镜+后视镜前移 视野很好 运动相机 Insta360影石ONER双镜头版 行车记录仪 喜郎MX901,HFK-HM501,其实没有必要带屏幕 喜郎MX901 保险盒在坐桶下,前面走线较麻烦,后面粘在尾架上 补胎工具 - 轮胎 增强湿地抓地力,倍耐力天使,米其林city - 轮胎打气工具 小米充气泵1s 平时打个气压还是很好用的 胎压检测仪 KEVTUT3,建议迷你传感器,重量对轮胎旋转有影响 - 尾箱 品牌:loboo,shad shad 48L 通勤不用,但平时去超市买个东西还是很能装的 尾箱内衬 避免颠簸时,车锁和头盔在尾箱内乱晃,导致各种划痕 淘宝尾箱内衬 尾箱架 品牌:群尾 普通尾箱架 尾箱支撑杆 - 坐桶内衬 淘宝坐桶内衬 坐桶隔热 - 坐桶橡胶垫螺丝垫片 内径1cm,外径2cm - 坐桶灯 考虑使用户外照明小灯 - 保险杠 品牌:群尾 群尾保险杠 主要作用还是原地倒车的时候能防护,作用有限,拆除 挡泥板延长 - 大防滑边撑 - 高风挡 高度需要实际看 老李车行,15cm高风挡 挡风效果很好,但雨天的时候很影响视线,拆除 合金折叠挂钩 - 合金牛角 原厂牛角太高,左侧牛角倒车变形 淘宝牛角 好看,不过还是高 刹车片 车力屋紫片 - 传动盖子 喷漆改色 - 防盗机油尺 - 排气管防烫板 - 刷ecu 调节风扇启动温度,从5格启动变为4格启动 - 散热开口 - 油箱盖透气阀 加油时,油箱压力大,喷气。应该选择小号的透气阀 淘宝透气阀 不再有热车开油箱盖喷气的情况 单向阀 - 加强版水箱 - 压力轴承 - 防冻液 换沸点高的 - 避震 前减触底,后减太硬 -
车牌
京 A
- 目前只能买到,市场价大概 30w。
京 B
办理限制
- 不可上牌的户口或居住证:东城、西城、海淀、朝阳、丰台、石景山。
- 可上牌的户口或居住证:通州、昌平、房山、门头沟、大兴、顺义、怀柔、密云、延庆、平谷。
限行
- 2021 年 5 月 9 日起北京京 B 摩托车新规,
- 长安街及其延长线(五棵松桥至四惠桥)、广场东侧路、广场西侧路、人大会堂西路、府右街、南长街、北长街、南池子大街、北池子大街。
- 西四东大街、西安门大街(西四南大街至西什库大街)、西黄城根北街、西黄城根南街。
- 四环路(不含辅路)以内道路全天禁止京 B 号牌摩托车行驶。
- 门头沟,国道南辛房路口至王平路口段、南赵路、天门山路、瓜草地路、南辛房村中街、焦岭路、赵家台路、妙峰山路、南樱路、禅涧路、玫瑰园路、南东路、上苇甸路、果园环路、上果路、炭厂大街、上苇甸环路、大禅路、大琅路全天禁止摩托车通行。
- 违反摩托车禁限行规定,处 100 元罚款,记 3 分。
- 详细可参考moyou.club 限行政策。
上牌流程
- 可交给车行代办。
- 自己上牌可以参考小白京B私户摩托车上牌历程,北京摩托车京B牌照上牌流程-20210406。
保险
- 具体的险种可以参考摩托车保险。
- 交强险
- 三者
- 人身意外伤害
- 车损险
- 盗抢险
其他
- 凯励程
- 摩托助手
车行
- 一些口碑不错的车行,北京可以参考最差车行排行。
- 老李车行
- 两轮族摩托车行
维护表
item desc 保养 磨合期:500km、1500km换机油;后续每2000km换机油、机滤、空滤 前1000km 不超过maxspeed80% 汽油 95号或以上 前轮胎压(带乘客时) 2bar(2bar) 后轮胎压(带乘客时) 2.2bar(2.5bar) 空气过滤器 肥皂水清洗,汽油+空气过滤海绵油浸泡后直接装回 总结
- 裸车 19980,预期全部办完(包括装备 25000)。
- 实际花费高于预期,落地 23618,装备和改装全部加起来大概 7000。
- 改装其实花了不少钱和精力,那直接买 3w 的踏板是否会避免这部分开销呢?我感觉明显不可能,毕竟总想着折腾折腾。
- 骑行感受和通勤体验以后更新。
骑行体验 2022-04-17 Sunday
行程
总行程8234公里
平均行程37.89km/天
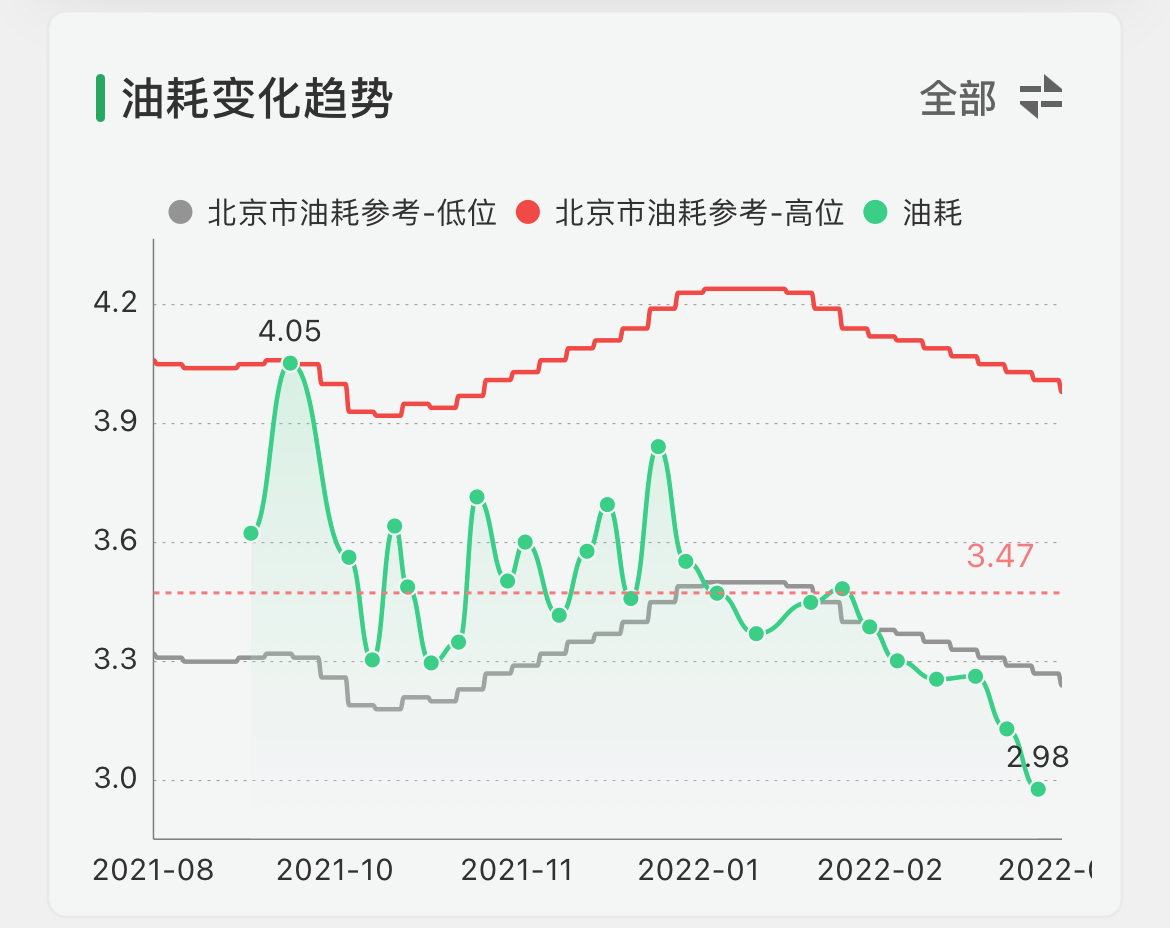
油耗
平均油耗3.46L/100km
平均油费0.28元/km
累计油费2309.76元
累计加油285.74L
油耗变化趋势
![IMG_2450.jpeg]()
加油详情
日期 时间 里程 油价 金额 实付 燃油标号 是否加满 是否亮灯 上次漏记 备注 2021/09/17 21:26 315 7.42 86.29 86.29 95 是 是 是 2021/09/27 22:29 602 7.49 77.9 77.9 95 是 否 否 2021/10/12 21:42 887 7.79 89.97 89.97 95 是 否 否 2021/10/18 21:43 1187 7.79 83.27 83.27 95 是 否 否 2021/10/24 14:07 1394 8.04 54.99 55 95 是 否 否 2021/10/27 21:34 1651 8.04 75.25 75.25 95 是 否 否 2021/11/02 21:55 1909 8.04 72.36 72.36 95 是 否 否 2021/11/09 21:56 2182 8.04 72.36 72.36 95 是 否 否 2021/11/14 14:37 2454 8.04 73.24 73.24 95 是 否 否 2021/11/22 10:10 2721 7.96 78.96 78.96 95 是 否 否 2021/11/26 22:06 3025 7.96 84.77 84.77 95 是 是 否 2021/12/05 14:41 3306 7.59 76.81 76.81 95 是 是 否 2021/12/12 17:09 3589 7.59 73.39 73.39 95 是 否 否 2021/12/17 21:55 3883 7.59 79.85 79.84 95 是 是 否 2021/12/23 21:54 4156 7.48 75.47 75.47 95 是 否 否 2021/12/30 22:00 4413 7.48 66.5 66.49 95 是 否 否 2022/01/06 22:21 4679 7.6 77.67 77.67 95 是 否 否 2022/01/14 21:49 4963 7.6 76.68 76.68 95 是 否 否 2022/01/24 22:21 5272 7.9 84.77 84.76 95 是 是 否 2022/02/07 20:12 5577 8.16 83.89 83.88 95 是 是 否 2022/02/15 21:58 5884 8.16 86.41 86.41 95 是 是 否 2022/02/22 21:41 6192 8.34 89.49 89.48 95 是 是 否 2022/03/01 22:38 6517 8.34 91.82 91.82 95 是 是 否 2022/03/11 23:09 6868 8.56 99.21 99.21 95 是 是 否 2022/03/21 22:03 7208 9.21 101.95 101.95 95 是 是 否 2022/03/29 21:56 7535 9.21 98.27 98.27 95 是 是 否 2022/04/06 22:09 7865 9.3 96.07 96.06 95 是 是 否 2022/04/14 21:58 8234 9.3 102.21 102.2 95 是 是 否 骑行体验
182kg的车重,刚骑车的那段时间,人力推车、挪车、倒车时扶车很困难,后面掌握了一点技巧后容易了一些,但仍然比较费劲。如果是路滑的情况下,那就是地狱难度了。
低速的骑行体验一般,2500转以下震动大,有皮带打箱体的情况。
速度起来以后,车辆的骑行品质很棒,震动小,震动颗粒感很细,感觉车子很稳。我觉得就凭这一点,这车很值。
气温高时,能闻到汽油味。
指针时速表时不时的存在不归零的情况。
水温到5格时风扇才会启动,虽然没什么问题,但是6格是高温报警,水温焦虑。
减震真的很一般,低速的情况下还行,一旦快一点减震和没有一样。前减软且行程短,速度快的时候过大坑容易触底;后减硬,过大小坑体验都较差。