6.824 2018 Lecture 5 Fault Tolerance Raft
Readings - In Search of an Understandable Consensus Algorithm (Extended Version) (to end of Section 5)论文
Introduction
共识算法(Consensus algorithms)允许一组机器作为一个一致的组工作,这个组可以在某些成员失败的情况下存活。Paxos是过去10多年最常被讨论的共识算法,但是难以理解且不便于实现。提出Raft的主要目标是可理解性。通过解耦leader选举、log复制和安全,以及减少状态空间,来增加可理解性。
多副本状态机(Replicated state machine)与共识算法 共识算法常常出现在多副本状态机的讨论中。
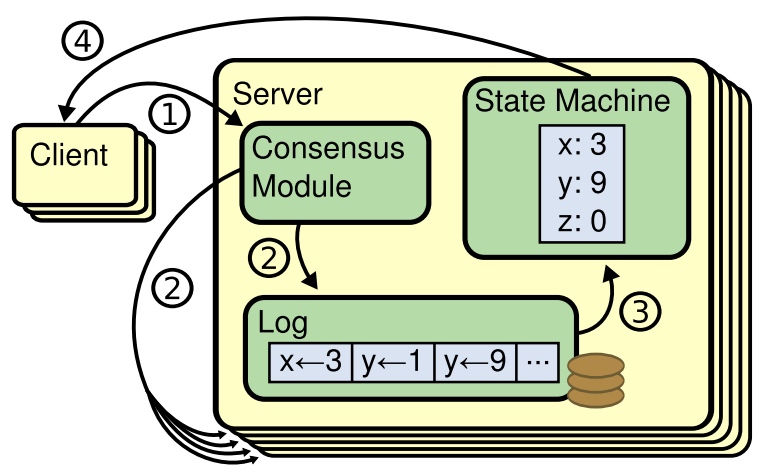
多副本状态机常用于解决分布式系统中的各种容错问题,使用复制log来实现,每个状态机以相同的顺序执行相同的命令,最终算出相同的状态和结果。保证replicated log的一致是由共识算法来实现的。
共识算法一般有以下几个特征: * 安全:非拜占庭条件(网络问题、丢包、乱序)下,不返回任何错误的结果。 * 可用性:大多数server可用,则系统整体可用。 * 不依赖时间来保证日志的一致性。 * 大多数server执行完毕则返回,少量慢server不影响系统性能。
Raft
raft的工作过程是,首先选举leader,leader会负责管理replicated log。leader接受来自client的log,复制到其他机器,并在安全的时候通知其他机器把log输入状态机。
raft可以解耦为以下三个部分: 1. leader选举(Leader election) 2. 日志复制(Log replication) 3. 安全(Safety)
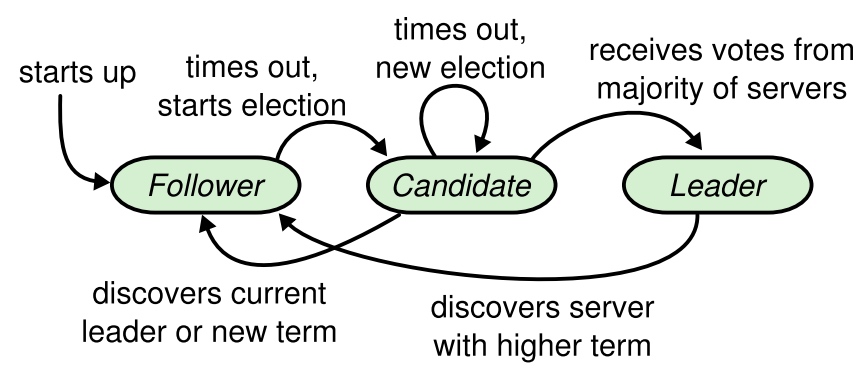
在理解这三个部分前,有几个基本概念需要知道, server 状态 * leader:只能有一个leader * follower:只响应来自其他server的请求 * candidate:用于选举
时间 raft把时间分为terms,term由一个递增的数字标识,表示current term。每个term以leader选举作为起始,如果未选举出leader,那么下一个term继续选。term内选举出的leader管理集群直到term结束。
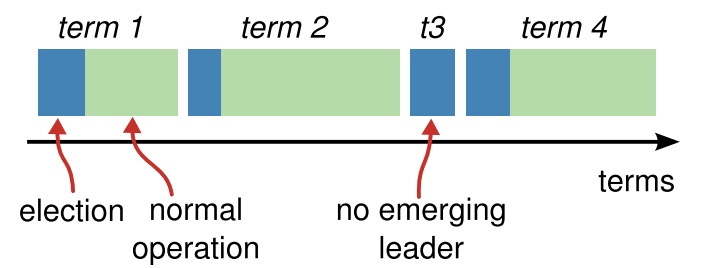
不同的server可能观察到不同的term转换,server使用current term(在server通信的时候发送)作为逻辑时钟,来确保能够探测到过期的信息。
通信 使用rpc。基本的共识算法使用两种rpc, 1. RequestVote RPCs:candidates调用,来进行拉票,用于选主。 2. AppendEntries RPCs:leader发起,用于复制日志和心跳。
leader选举(Leader election)
选举过程为,follower在election timeout内都没有收到leader的通信,则转换为candidate状态,并自增当前term、为自己投票、向其他server发送RequestVote RPCs。candidate维持在这个状态,直到下列情况出现: 1. 获得了相同term的多数派的投票,赢得选举。 一旦candidate赢得选举,就转换为leader,并向其他server发送heartbeat,宣告leadership。 2. 收到AppendEntries RPCs,其他candidate赢得了选举,成为leader。 1. 如果leader的term >= 自己的term,那么这个leader是合法的,自己转换为follower状态。 2. 如果leader的term < 自己的term,那么拒绝这个rpc,自己维持在candidate状态。 3. election timeout后,未获得足够的选票。 多个candidate可能同时发起选举,发生了split vote,导致任何一个都无法获得多数派的投票。自增term,开始下一次选举。
在下面的状态图中,状态转换的上方表示触发转换的event,下方表示发生转换时执行的action。
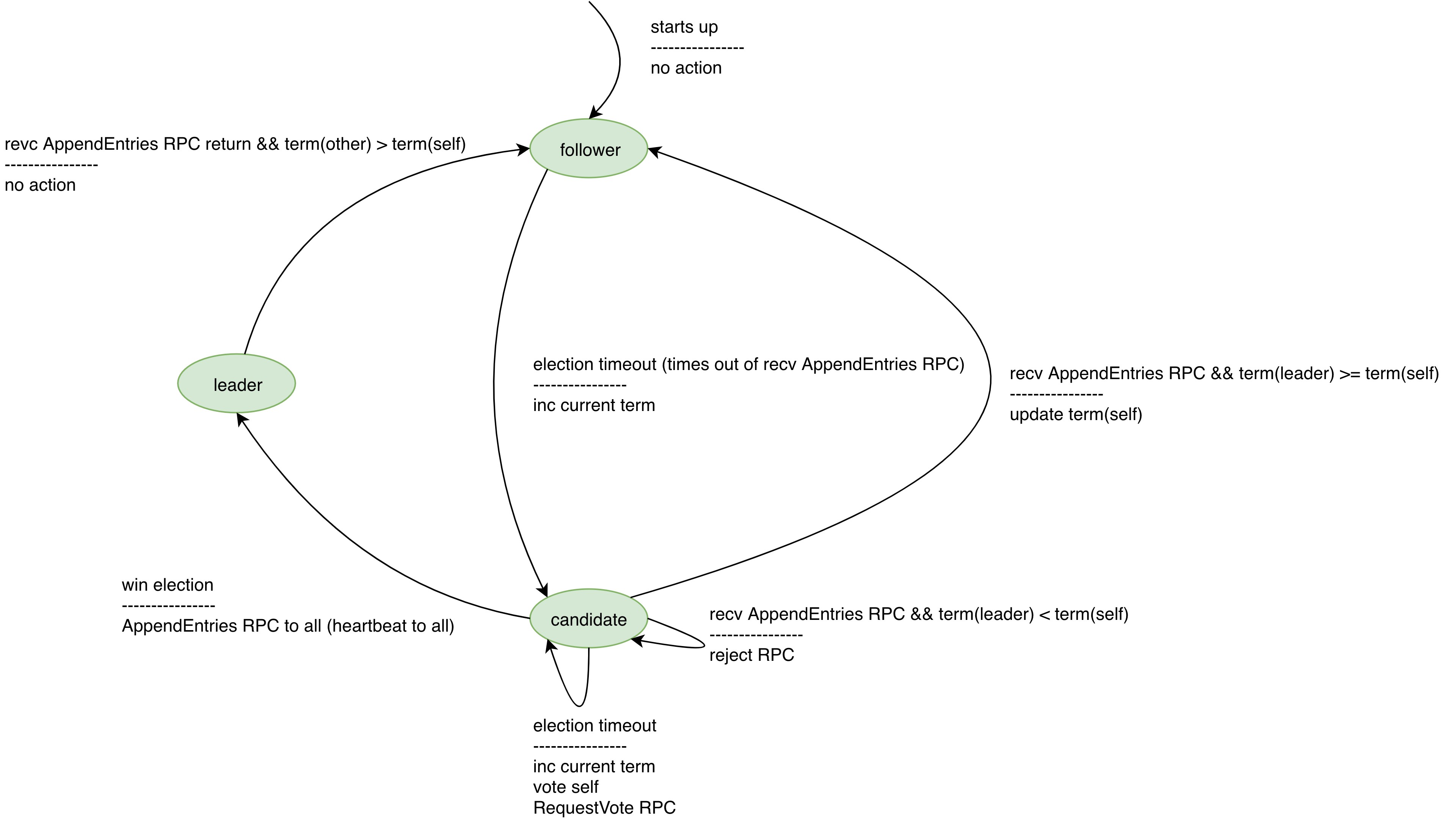
选举安全性: * 在每个term内,每个server只能至多为一个candidate投票。
在选举过程中,raft使用随机election timeout来保证, * split
votes(没有任何candidate能获得大多数投票)会很少出现。
比较常见的是,C先timeout,然后投票给自己,并发送RequestVote
RPCs,最终win。 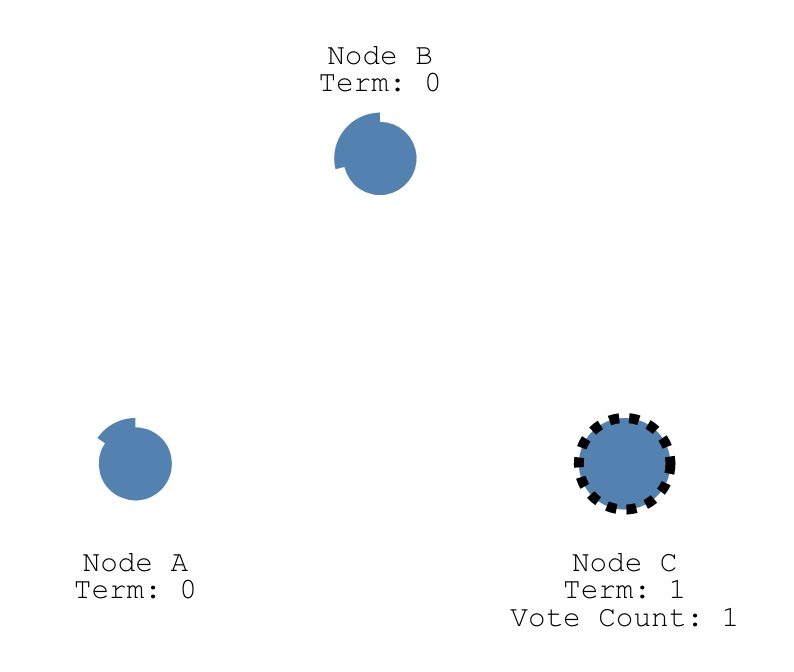 * 且split votes能够被快速解决。如果出现split
votes,candidate先等待随机election timeout。
* 且split votes能够被快速解决。如果出现split
votes,candidate先等待随机election timeout。
日志复制(Log replication)
如何复制 1. leader追加log entry。 2. AppendEntries RPC。 3. 当log entry被安全复制(成为committed log entry,leader更新commit index), * leader apply log entry,然后返回结果到client。 * leader AppendEntries RPC通知follower committed entry,follower apply log entry。
如果follower失败、运行缓慢、丢包,leader重试AppendEntries RPC(就算leader已经返回client结果),直到所有follower最终收到所有log entry。raft保证了committed entry是持久化的,且最终能被所有可用的状态机执行。
那什么时候才算log entry被安全复制?当创建log entry的leader把entry复制到大多数server上以后。这同时也提交了在leader中所有先前的log,包括被前leader创建的log。
应对出错 raft在复制log时会维护如下性质来保证Log Matching Property(log consistency), * 如果两个entry在不同的log中有相同的index和term,那么它们的cmd是相同的。 因为leader至多只创建一个带有相同index和term的entry,且entry不会在log中改变位置。 * 如果两个entry在不同的log中有相同的index和term,那么所有先前的log都是相同的。 consistency check:AppendEntries RPC发送新的entry时,会包含前一个entry,如果follower没有找到与前一个entry相同的index和term,那么follower不会写入新的entry。
根据以上两点,结合数学归纳法可知,Log Matching Property可以被满足。在正常情况下,leader和follower的log是保持一致的。
如果leader或follower崩溃引起了log不一致,如何恢复一致性?leader会强制follower复制自己的log,
1.
leader维护了{follower: nextIndex},表示下一个将会发送到follower的entry。
2.
leader启动时,将nextIndex置为max(self log index) + 1。
3. 如果follower的日志不一致,那么接下来的AppendEntries RPC consistency
check会失败。leader会将nextIndex - 1并重试,直到成功。
安全(Safety)
任何实现了日志复制的系统,都必须满足:一旦entry已经applied到状态机,那么任何其他状态机都不能为这条entry apply一个不同的值。
截止目前所描述的leader选举,存在的问题是,如果follower未收到leader的提交,那么当它成为leader以后,就会用自己的log覆盖其他server的。
选举约束 任何基于leader的共识算法,leader必须最终包含所有committed entry。raft需要保证所有committed entry,都出现在后续每个新的leader中,而这个保证确保了本节内容开头的安全性要求。
在选举的时候,使用voting process来避免未包含所有committed entry的candidate赢得选举。由于candidate在选举的时候需要联系大多数server,即只需要求每个committed entry必须出现在至少一个server(选举时联系的server)里面即可(抽屉原理)。
如果candidate包含的日志与大多数server包含的log至少一样新,那么这个candidate就包含了所有的log。具体判断方法是, 1. 在RequestVote RPC进行投票时,rpc包含了candidate最后一个entry的index和term。 2. 如果voter(收到rpc call的一方)的log是更新的,即, \[(lastTerm_v > lastTerm_c) || ((lastTerm_v == lastTerm_c) \\&\\& (lastIndex_v > lastIndex_c))\] 那么voter拒绝此次投票。
提交上一个term的entry 新leader能否直接提交上一个term的entry?
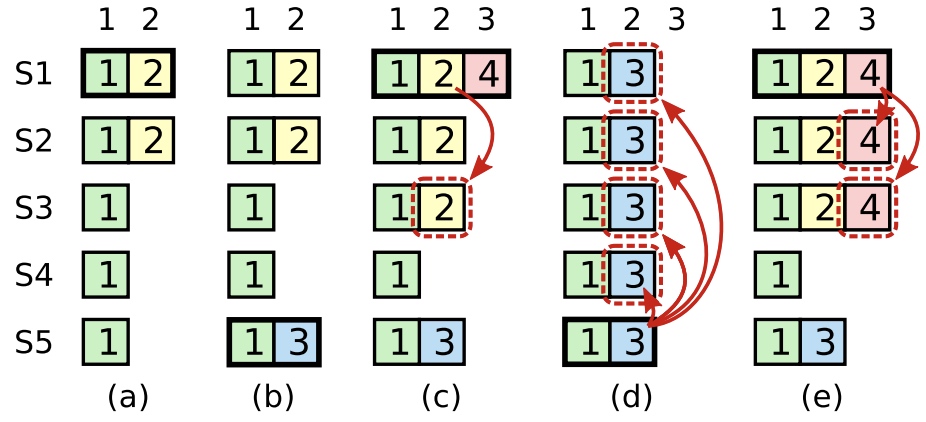
c中s1成为term4的leader后继续复制term2的日志index2,此时日志已经复制到大多数机器上。按照之前的规则,s1可以认为日志已经是committed。但如果接着s5成为了leader(接受s3和s4的投票),s5会覆盖s1已经commit的日志。
因此不能仅通过副本数判断先前term的日志是不是committed,还需要满足至少有一个属于当前term的log也复制到大多数server,才能认为是。
follower和candidate崩溃
raft rpc是幂等的,leader无限重试。
时间和可用性
raft的安全性不依赖时间。但是系统的可用性依赖时间,这里有尤其指的是leader选举。election timeout需要满足下面的要求,raft才能选举并保持一个稳定的leader,
\[broadcastTime \ll electionTimeout \ll MTBF\]
Leadership transfer
本质上还是使用leader选举的机制,通过主动触发目标server进行选举来实现来迁移,与后面的配置变更不同。过程如下: 1. 旧leader暂停服务。 2. 旧leader进行正常的日志复制过程,把log复制到目标server。 3. 旧leader发送TimeoutNow到目标server,触发目标server开始选举(相当于调快了timer,触发了election timeout)。 4. 目标server大概率会比其他server先发起选举,并成为下一个term的leader。 5. 选举成功后,旧leader收到heartbeat,出让leadership,至此transfer完成。
如果迁移过程未在一个election timeout内完成,那么终止迁移。如果迁移成功了,但是旧leader误以为失败了,那最坏情况是进行一次额外的选举。
问题
日志复制时每个步骤都有可能出现错误,如何处理? raft并不允许“false positives”的出现(返回client执行成功了,但实际上没有成功),但是可能会有“false negatives”的出现,告知client失败了,但实际上是成功了。为了避免false negatives,client必须重试直到成功,且每次只能有一个未完成的command,相应地,raft也必须提供去重机制。
为什么不能直接复制上一个term未committed的entry?
raft为何能够防止脑裂? 2f+1个server,成为leader需要获得大多数server(f+1个)的投票。如果发生网络分区,必然有一个partition的分区少于f+1个。这个分区里面,
- 如果没有leader,那么也不可能选举出leader。
- 如果有leader,由于日志无法被安全复制,因此不会对client做出任何承诺(不会成为committed entry,也不会被apply到状态机)。
为什么需要leader?
- 简化复制日志的过程。
- 保证所有的副本都以相同的顺序执行相同的命令。
server变为candidate后会发生什么? 开始选举:inc term,vote self,发送RequestVote RPC。可能结果如下,
- 赢得选举。 变为leader。
- 选举失败,收到来自其他leader的AppendEntries RPC。 变为follower。
- 既没有赢得选举,也没有收到来自其他leader的AppendEntries RPC。 维持candidate。election timeout,开始下一次选举。 如果一直无法获得大多数server的投票,这个过程会一直重复,term会一直增加。 此时,如果client有请求会发生什么?
如何保证同一个term内只有一个leader?
- leader需要获得来自大多数server的投票。
- 在同一个term内,每个candidate只能投票一次。
- 在同一个term内,至多只有一个server能获得大多数server的投票(即使出现网络分区)。
什么情况下选举会失败?
- 大多数server都失败了。
- 两个server获得了相同票数(例如:2f+1个server,挂了一个server)。
选举失败会发生什么? election timeout,开始下一次选举。
如何设置election timeout?
- \(broadcastTime \ll electionTimeout \ll MTBF\)
- random
- 至少是几个heartbeat间隔
replicated和committed entry的区别?
- replicated是做了复制,可能被覆盖。
- committed,已提交,不会丢失。
每个副本的日志会完全一致吗? 不会,可能落后,可能会有临时的不一致。但最终会一致,且状态机执行的命令是一致的。
为什么leader不能直接提交上一个term的entry?以及如何避免直接提交带来的问题? 提交时,需要等到至少一个当前term的entry也安全复制以后。
leader在什么时候覆盖follower的entry是合法的? uncommitted entry。
leader覆盖follower的entry时,可能会覆盖committed entry吗? 不会。
- 先看entry成为committed时,发生了什么。log entry需要安全复制,即发送到大多数server上。
- candidate成为leader,需要联系大多数server,以保证自身的log与大多数server的一样新(选举约束)。因此成为leader的candidate一定包含了所有committed entry。
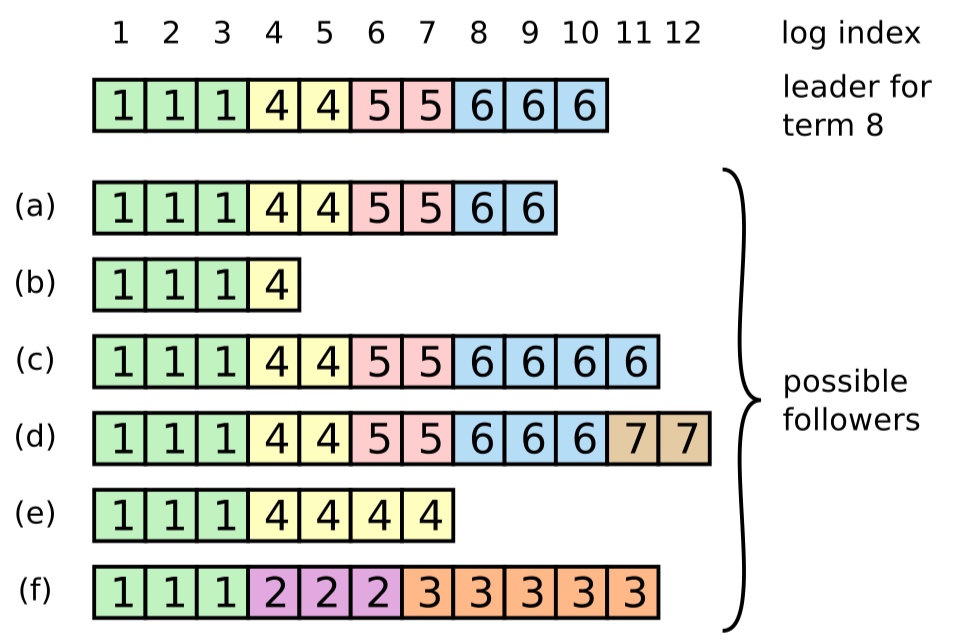
如果下图中的leader(for term 8)挂了,a、d和f,哪个会被选举为leader?谁投的票?新leader产生后,哪些entry一定会保留下来?
![-w478]()
a-f每个server最多可能获得投票的情况如下: a:a,b,e,f b:b,f c:a,b,c,e,f d:a,b,c,d,e,f e:b,e f:f
所以a或d可能成为leader,一定会保留下的log是111445566。
如果server刚开始选举,此时收到了来自leader的AppendEntries RPC(假设leader与这个server都是处于同一个term),此时要怎么处理?
- candidate成为leader后,应该立即发送心跳来避免发生多余的选举。
- 如果发生这个情况,由于term一样,leader会忽略RequestVote RPC。
如果leader完成复制,更新自身的commit index,且完成了apply,但在通知follower commit index前挂了(或丢失了leader资格),这个entry最终会丢失吗?
lastApplied是否应该做持久化? 这个地方有点争议。在ongardie/dissertation的Errata中,指明了lastApplied是否做持久化应该与状态机一致。但在Raft Q&A中的说法是,状态机如果做持久化,那么也应该负责记住执行了哪些log。
follower拒绝AppendEntries RPC时,如何快速的解决冲突? follower拒绝时,返回冲突entry的term,以及这个term首个entry的index。
- 如果leader有这个entry,那么移动nextIndex到冲突的那个entry。
- 如果leader没有这个entry,那么移动nextIndex到那个term的首个index。
还可以使用二分法,查找首个冲突的entry,这可以实现在最坏情况下的最佳时间复杂度。
Lab 2A: Raft
锁的使用建议
这个lecture说了几点关于锁的建议,我觉得最重要的一点是,
Be careful about assumptions across a drop and re-acquire of a lock. One place this can arise is when avoiding waiting with locks held.
在减少锁的粒度的时候,可能也把变量的write和read分开了,进而导致在read的时候,变量已经被其他线程改变了。